User question: what does "canonical" mean?
Hi all,
Over time, I've frequently encountered this question, as well as numerous instances where misunderstandings about the term "canonical" and its use in SEO have led to problems, confusion, and a great deal of wasted time.
I've been meaning to write about the concept of canonical for a while and this week, a comment at the end of a support ticket finally prompted me to do so. The comment was :
I need to learn more about what "canonical" means
The thing is, canonical is used (mostly) in two different ways and they seem to contradict each other:
- a page is canonical (or not)
- a page has a canonical tag
The confusing part is that:
when a page has a canonical tag, it's usually because it's not canonical
How is that possible and should you care anyway?
What's the problem?
One issue most search engines have is if the same page can be accessed via multiple addresses. The address of a page is called a URL, and it's the line starting with https://www.yoursite.com/..... in the address bar of your browser.
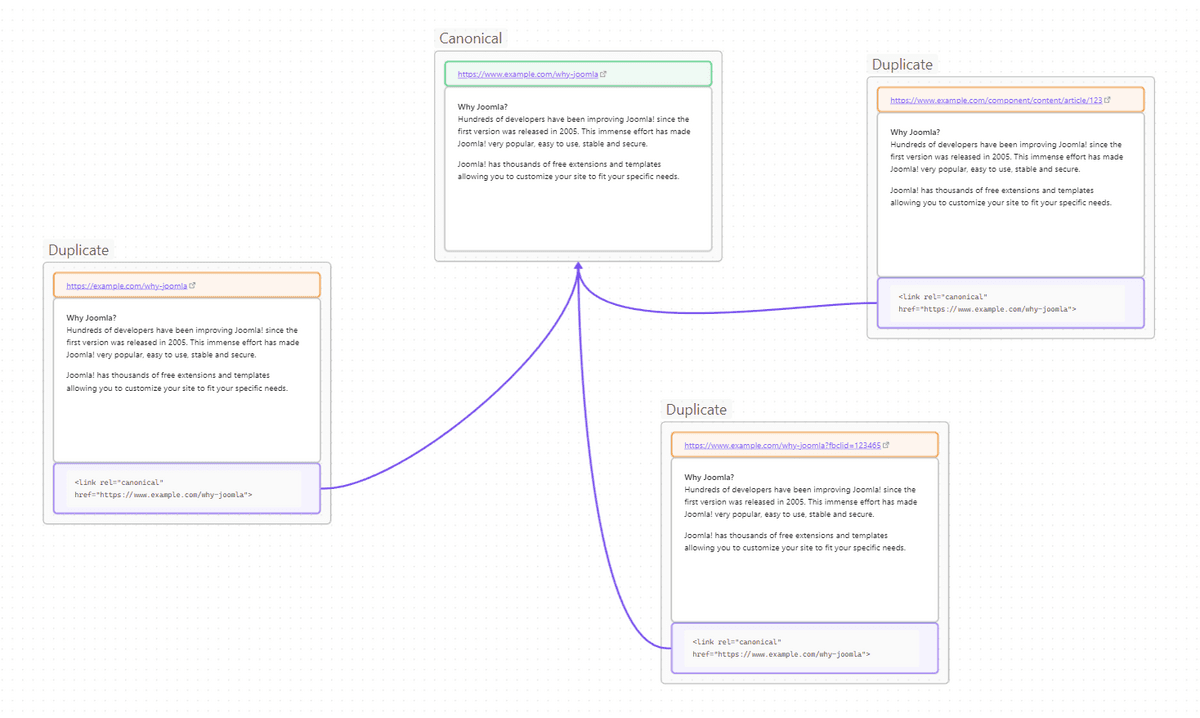
For instance, on a typical Joomla website, it's quite possible that all the following URLs show in fact the same article:
- https://www.example.com/why-joomla
- https://example.com/why-joomla
- https://www.example.com/Why-JOOMLA
- https://example.com/why-joomla?fbclid=1693sdfdsfgdgdgfdjhgfdjhfd
- https://www.example.com/blog/why-joomla
- https://www.example.com/component/content/article/123
It will look a bit like that:
If that happens, then:
- search engines have to load and analyze all these pages, because they think they are different pages - and they can't tell they are the same until they analyzed them all
- the SEO "quality" signals - backlinks from other sites typically, but also content analysis - are split between different URLs, while in fact they relate to the same page
- they don't know which URL is the "desired" one
On small sites ( a few hundred pages maybe), they don't care too much, they have enough "power" to load all pages and see that they are the same. They pick one URL and decide it's going to be the main one. And they can assign all quality signals to that main URL.
That main URL is called the "canonical URL" for that page, and the other pages in the same "cluster" are called "duplicates".
In our example, Google may decide that https://www.example.com/why-joomla is the canonical URL for that article.
If they find a link from a reputed website to that article, but using the https://www.example.com/blog/why-joomla URL, they will:
- still consider this link a good SEO signal
- despite the link being https://www.example.com/blog/why-joomla, they will count it as a quality signal for https://www.example.com/why-joomla, the canonical URL
That way all quality signals are "concentrated" on one URL. They still count despite being for another URL.
Now on larger sites, this is a bigger issue because:
- Google may stop looking at (new) pages on your site if they think there's a chance they are duplicates of known pages, or just because you have a history of having duplicates. They will also come back less often to check for changes.
- They may pick the wrong canonical URL, one that you don't want
- they may not be able to recognize that all these URLs are in fact for the same content, and you may lose some quality signals
Of course this is an issue because they may miss some or a lot of your content. Or they may waste time on some useless content and not bother about your real, good, new content.
What to do about it? and should I?
Duplicate content is going to be an issue only for larger sites usually. And of course, 4SEO has its auto-canonicalization feature which detects that situation and adds specific metadata to your site pages to fix the problem:
The metadata code telling search engines which page is canonical and which page is a duplicate is called a rel canonical link.
Back to our example, let's say you - or Google - load the page at: https://www.example.com/component/content/article/123 in your browser.
Joomla happily renders the article but 4SEO sees something's not right and adds this code to the page content:
<link rel="canonical" href="https://www.example.com/why-joomla"/>
Note: this code is invisible to visitors, it's a bit like your meta description or other metadata elements.
Here is our previous set of URLs with the added rel canonical elements:
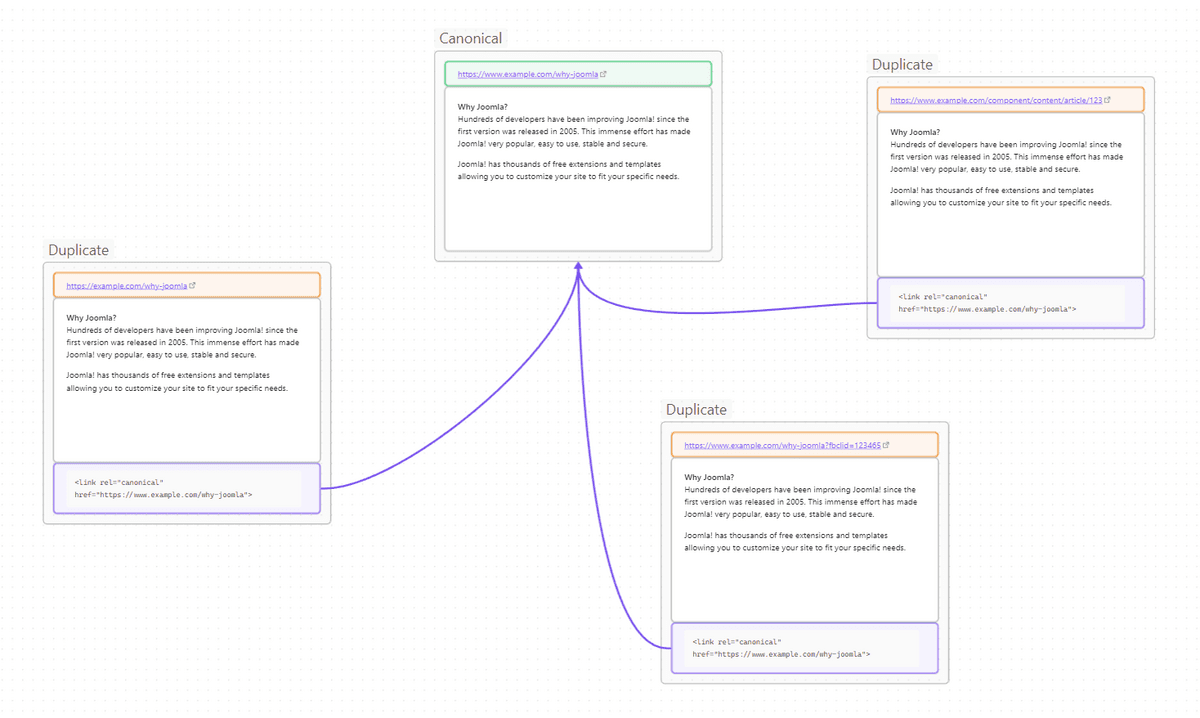
Google sees this code, which tells them:
- you loaded the page at https://www.example.com/component/content/article/123
- it works fine
- but this page is the same as the one at https://www.example.com/why-joomla
- we'd prefer you to use https://www.example.com/why-joomla instead
With proper rel=canonical links in place, Google gets a strong hint about which page it should or should not analyze and rank.
The short story
- some pages on your site may be accessed through multiple addresses
- this is usually fine on sites with at most a few hundred pages
- it can cause significant SEO damage on large sites
- one address should be considered the canonical address for a page
- other addresses are called duplicates
- when a page is accessed using a duplicate address, it should have a canonical tag linking back to the canonical page address
- the canonical page can have a canonical tag pointing at itself. This is not required at all, what matters is that duplicates have one
Hope that was useful, please feel free to ask questions in the comment!
Cheers,
Yannick